
{kind=link}

Yandex has recently made a significant contribution to the recommender systems community by releasing Yambda, the world’s largest publicly available dataset for recommender system research and development. This dataset is designed to bridge the gap between academic research and industry-scale applications, offering nearly 5 billion anonymized user interaction events from Yandex Music — one of the company’s flagship streaming services with over 28 million monthly users.
Why Yambda Matters: Addressing a Critical Data Gap in Recommender Systems
Recommender systems underpin the personalized experiences of many digital services today, from e-commerce and social networks to streaming platforms. These systems rely heavily on massive volumes of behavioral data, such as clicks, likes, and listens, to infer user preferences and deliver tailored content.
However, the field of recommender systems has lagged behind other AI domains, like natural language processing, largely due to the scarcity of large, openly accessible datasets. Unlike large language models (LLMs), which learn from publicly available text sources, recommender systems need sensitive behavioral data — which is commercially valuable and hard to anonymize. As a result, companies have traditionally guarded this data closely, limiting researchers’ access to real-world-scale datasets.
Existing datasets such as Spotify’s Million Playlist Dataset, Netflix Prize data, and Criteo’s click logs are either too small, lack temporal detail, or are poorly documented for developing production-grade recommender models. Yandex’s release of Yambda addresses these challenges by providing a high-quality, extensive dataset with a rich set of features and anonymization safeguards.

What Yambda Contains: Scale, Richness, and Privacy
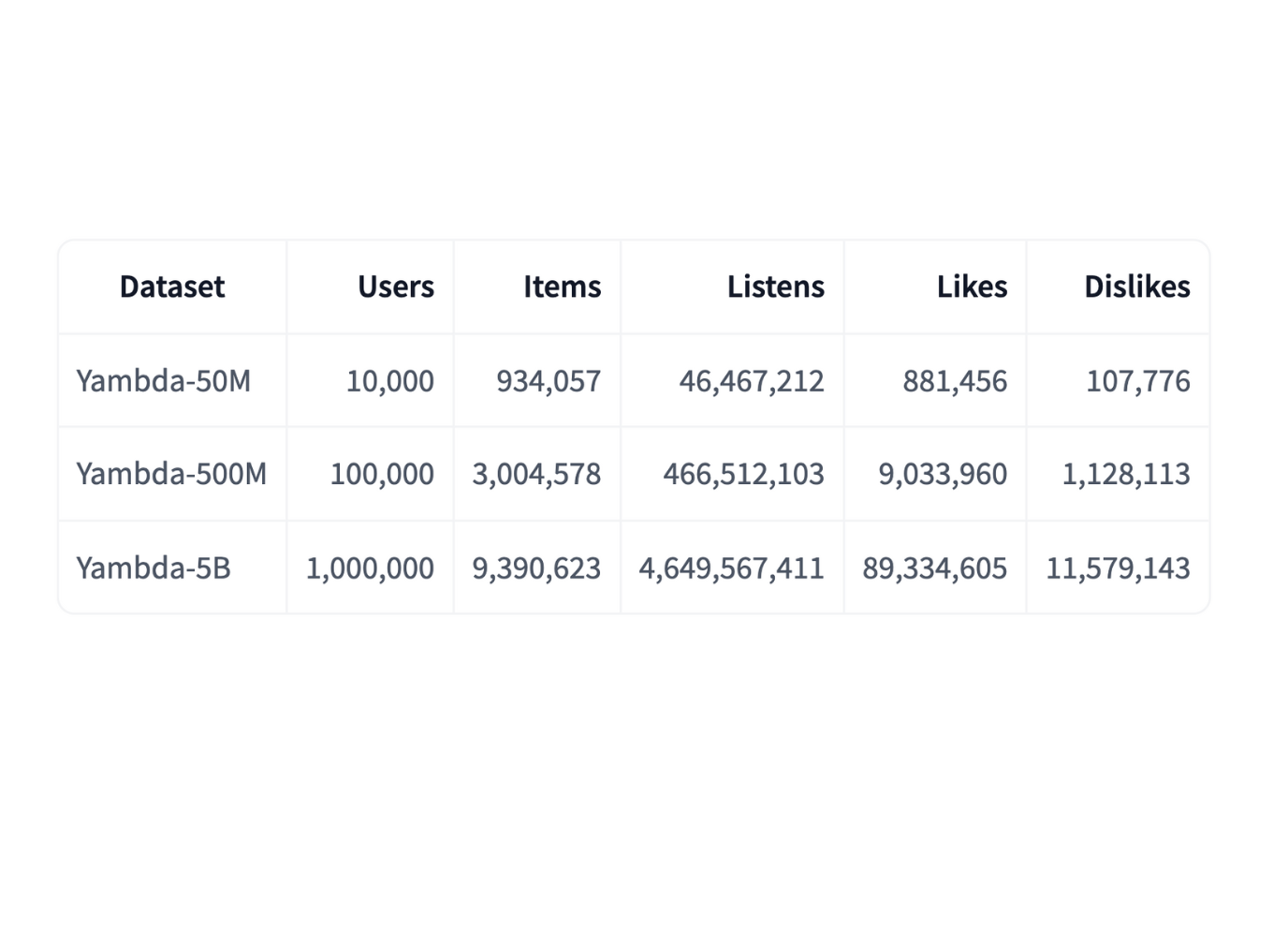
The Yambda dataset comprises 4.79 billion anonymized user interactions collected over a 10-month period. These events come from roughly 1 million users interacting with nearly 9.4 million tracks on Yandex Music. The dataset includes:
- User Interactions: Both implicit feedback (listens) and explicit feedback (likes, dislikes, and their removals).
- Anonymized Audio Embeddings: Vector representations of tracks derived from convolutional neural networks, enabling models to leverage audio content similarity.
- Organic Interaction Flags: An “is_organic” flag indicates whether users discovered a track independently or via recommendations, facilitating behavioral analysis.
- Precise Timestamps: Each event is timestamped to preserve temporal ordering, crucial for modeling sequential user behavior.
All user and track identifiers are anonymized using numeric IDs to comply with privacy standards, ensuring no personally identifiable information is exposed.
The dataset is provided in Apache Parquet format, which is optimized for big data processing frameworks like Apache Spark and Hadoop, and also compatible with analytical libraries such as Pandas and Polars. This makes Yambda accessible for researchers and developers working in diverse environments.
Evaluation Method: Global Temporal Split
A key innovation in Yandex’s dataset is the adoption of a Global Temporal Split (GTS) evaluation strategy. In typical recommender system research, the widely used Leave-One-Out method removes the last interaction of each user for testing. However, this approach disrupts the temporal continuity of user interactions, creating unrealistic training conditions.
GTS, on the other hand, splits the data based on timestamps, preserving the entire sequence of events. This approach mimics real-world recommendation scenarios more closely because it prevents any future data from leaking into training and allows models to be tested on truly unseen, chronologically later interactions.
This temporal-aware evaluation is essential for benchmarking algorithms under realistic constraints and understanding their practical effectiveness.
Baseline Models and Metrics Included
To support benchmarking and accelerate innovation, Yandex provides baseline recommender models implemented on the dataset, including:
- MostPop: A popularity-based model recommending the most popular items.
- DecayPop: A time-decayed popularity model.
- ItemKNN: A neighborhood-based collaborative filtering method.
- iALS: Implicit Alternating Least Squares matrix factorization.
- BPR: Bayesian Personalized Ranking, a pairwise ranking method.
- SANSA and SASRec: Sequence-aware models leveraging self-attention mechanisms.
These baselines are evaluated using standard recommender metrics such as:
- NDCG@k (Normalized Discounted Cumulative Gain): Measures ranking quality emphasizing the position of relevant items.
- Recall@k: Assesses the fraction of relevant items retrieved.
- Coverage@k: Indicates the diversity of recommendations across the catalog.
Providing these benchmarks helps researchers quickly gauge the performance of new algorithms relative to established methods.
Broad Applicability Beyond Music Streaming
While the dataset originates from a music streaming service, its value extends far beyond that domain. The interaction types, user behavior dynamics, and large scale make Yambda a universal benchmark for recommender systems across sectors like e-commerce, video platforms, and social networks. Algorithms validated on this dataset can be generalized or adapted to various recommendation tasks.
Benefits for Different Stakeholders
- Academia: Enables rigorous testing of theories and new algorithms at an industry-relevant scale.
- Startups and SMBs: Offers a resource comparable to what tech giants possess, leveling the playing field and accelerating the development of advanced recommendation engines.
- End Users: Indirectly benefits from smarter recommendation algorithms that improve content discovery, reduce search time, and increase engagement.
My Wave: Yandex’s Personalized Recommender System
Yandex Music leverages a proprietary recommender system called My Wave, which incorporates deep neural networks and AI to personalize music suggestions. My Wave analyzes thousands of factors including:
- User interaction sequences and listening history.
- Customizable preferences such as mood and language.
- Real-time music analysis of spectrograms, rhythm, vocal tone, frequency ranges, and genres.
This system dynamically adapts to individual tastes by identifying audio similarities and predicting preferences, demonstrating the kind of complex recommendation pipeline that benefits from large-scale datasets like Yambda.
Ensuring Privacy and Ethical Use
The release of Yambda underscores the importance of privacy in recommender system research. Yandex anonymizes all data with numeric IDs and omits personally identifiable information. The dataset contains only interaction signals without revealing exact user identities or sensitive attributes.
This balance between openness and privacy allows for robust research while protecting individual user data, a critical consideration for the ethical advancement of AI technologies.
Access and Versions
Yandex offers the Yambda dataset in three sizes to accommodate different research and computational capacities:
- Full version: ~5 billion events.
- Medium version: ~500 million events.
- Small version: ~50 million events.
All versions are accessible via Hugging Face, a popular platform for hosting datasets and machine learning models, enabling easy integration into research workflows.
Conclusion
Yandex’s release of the Yambda dataset marks a pivotal moment in recommender system research. By providing an unprecedented scale of anonymized interaction data paired with temporal-aware evaluation and baselines, it sets a new standard for benchmarking and accelerating innovation. Researchers, startups, and enterprises alike can now explore and develop recommender systems that better reflect real-world usage and deliver enhanced personalization.
As recommender systems continue to influence countless online experiences, datasets like Yambda play a foundational role in pushing the boundaries of what AI-powered personalization can achieve.
Check out the Yambda Dataset on Hugging Face.
Note: Thanks to the Yandex team for the thought leadership/ Resources for this article. Yandex team has supported and sponsored this content/article.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
