
{kind=link}

Video large language models (VLLMs) have emerged as transformative tools for analyzing video content. These models excel in multimodal reasoning, integrating visual and textual data to interpret and respond to complex video scenarios. Their applications range from question-answering about videos to summarization and video description. With their capacity to process large-scale inputs and provide detailed outputs, they are crucial in tasks requiring advanced comprehension of visual dynamics.
One key challenge in VLLMs is managing the computational costs of processing vast visual data from video inputs. Videos inherently carry high redundancy as frames often capture overlapping information. These frames generate thousands of tokens when processed, leading to significant memory consumption and slower inference speeds. Addressing this issue is critical for making VLLMs efficient without compromising their ability to perform complex reasoning tasks.
Current methods have attempted to mitigate computational constraints by introducing token pruning techniques and designing lightweight models. For example, pruning methods like FastV leverage attention scores to reduce less relevant tokens. However, these approaches often rely on static one-shot pruning strategies, which can inadvertently remove critical tokens necessary for maintaining high accuracy. Moreover, parameter reduction techniques frequently compromise the reasoning capabilities of the models, limiting their application to demanding tasks.
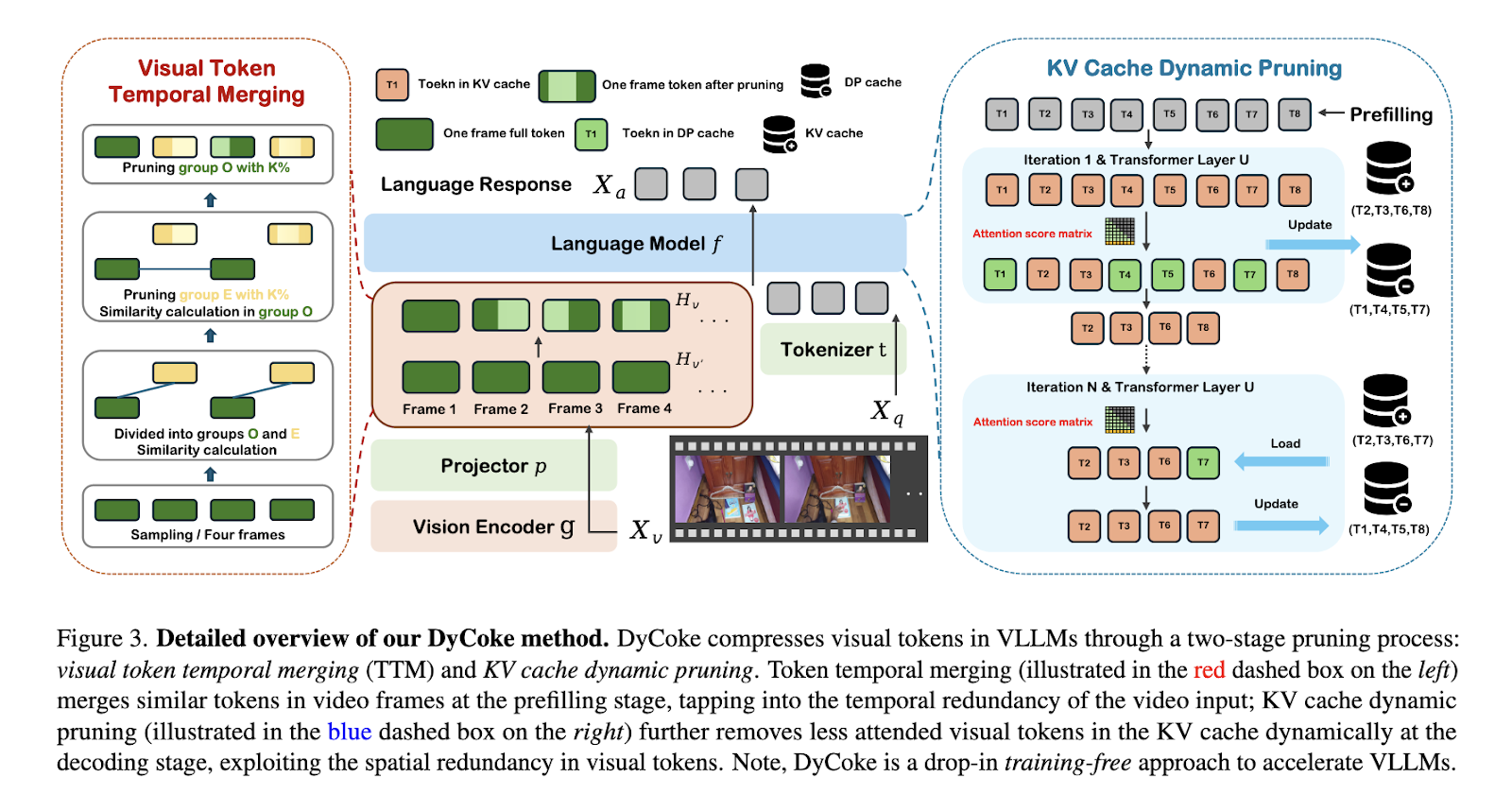
Researchers from Westlake University, Salesforce AI Research, Apple AI/ML, and Rice University introduced DyCoke, a novel method designed to dynamically compress tokens in large video language models. DyCoke adopts a training-free approach, distinguishing itself by addressing temporal and spatial redundancies in video inputs. By implementing dynamic and adaptive pruning mechanisms, the method optimizes computational efficiency while preserving high performance. This innovation aims to make VLLMs scalable for real-world applications without requiring fine-tuning or additional training.

DyCoke employs a two-stage process for token compression. Temporal token merging consolidates redundant tokens across adjacent video frames in the first stage. This module groups frames into sampling windows and identifies overlapping information, merging tokens to retain only distinct and representative ones. For instance, visual redundancy in static backgrounds or repeated actions is effectively reduced. During the decoding phase, the second stage employs a dynamic pruning technique in the key-value (KV) cache. Tokens are dynamically evaluated and retained based on their attention scores. This step ensures that only the most critical tokens remain, while irrelevant tokens are stored in a dynamic pruning cache for potential reuse. By iteratively refining the KV cache at each decoding step, DyCoke aligns computational load with the actual significance of tokens.
The results of DyCoke highlight its efficiency and robustness. On benchmarks such as MVBench, which includes 20 complex tasks like action recognition and object interaction, DyCoke achieved up to 1.5× inference speedup and a 1.4× reduction in memory usage compared to baseline models. Specifically, the method reduced the number of retained tokens to as low as 14.25% in some configurations, with minimal performance degradation. On the VideoMME dataset, DyCoke excelled in processing long video sequences, demonstrating superior efficiency while maintaining or surpassing uncompressed models’ accuracy. For example, with a pruning rate 0.5, it achieved a latency reduction of up to 47%. It outperformed state-of-the-art methods like FastV in maintaining accuracy across tasks such as episodic reasoning and egocentric navigation.
DyCoke’s contribution extends beyond speed and memory efficiency. It simplifies video reasoning tasks by reducing temporal and spatial redundancy in visual inputs, effectively balancing performance and resource utilization. Unlike previous methods that required extensive training, DyCoke operates as a plug-and-play solution, making it accessible for a wide range of video language models. Its ability to dynamically adjust token retention ensures that critical information is preserved, even in demanding inference scenarios.

Overall, DyCoke represents a significant step forward in the evolution of VLLMs. Addressing the computational challenges inherent in video processing enables these models to operate more efficiently without compromising their reasoning capabilities. This innovation advances state-of-the-art video understanding and opens new possibilities for deploying VLLMs in real-world scenarios where computational resources are often limited.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
🎙️ 🚨 ‘Evaluation of Large Language Model Vulnerabilities: A Comparative Analysis of Red Teaming Techniques’ Read the Full Report (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.